Before expanding on consistent hashing, let’s start with the term “hash function.” In the computing domain, a hash function takes some piece of data (known as a key) as input and produces another piece of data (known as hash code). The hash code is an integer value used to determine the index where the corresponding value will be stored in the table. Primarily, hash tables are used to store data, to reduce the data retrieval time.
The following illustration shows the working of a hash function:

Often, the size of a hash table becomes very large; this means it has to be split into several parts. Further, each part of the hash table is stored on a different server. A typical use case for a distributed hash table is the in-memory key-value cache, for instance, Redis.
The distribution of the hash table takes place by taking the modulo of the hash value with the number of servers. The resulting number represents the server where the original data against that specific key will be stored in a hash table on the server. The following illustration demonstrates the overall process:
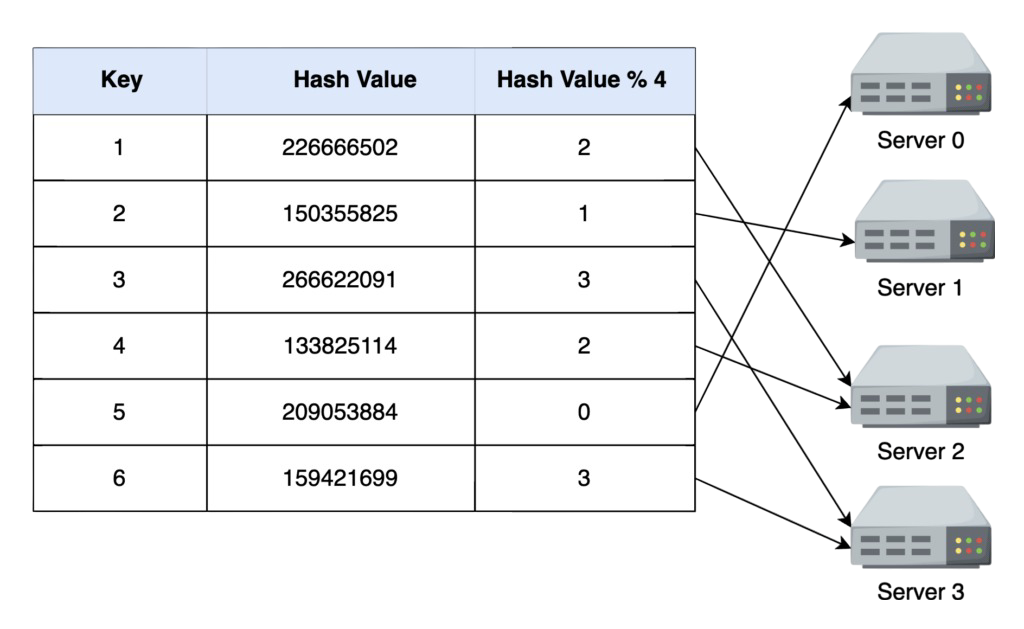
However, distributing a hash table across several servers comes with some complexities. For instance, if we want to increase or decrease the number of servers, we would be required to recompute the modulo of each value with a different number. For example, if there are 10000 servers and 5 go down, we must recompute the modulo of each hash value with 9995 instead of 10000. These repeated modulo operations reduce systems performance and hinder in scalability of the system.
Therefore, the solution to this problem requires a distributed strategy that shouldn’t directly depend on the number of servers. The strategy should also ensure that, when servers are added or removed, the relocation of keys should be minimized. One such distributed strategy is consistent hashing.
Consistent hashing
Consistent hashing is an effective technique for distributing the workload among a set of servers efficiently. It minimizes the number of keys to be remapped when a server is added or removed from the system (or cluster).
In consistent hashing, we imagine a circle where each point corresponds to a hashed value from 000 to n−1n-1n−1. Here, nnn represents all possible hash values, covering the full circle. Typically, nnn is chosen to be a number larger than the number of expected servers. Each server’s ID is hashed, and the hash value can be visualized as a point on the circle. Similarly, we also compute the hash of a key and find out where it lies on the circle. The corresponding data is then stored (or retrieved) in the next server encountered while traversing clockwise from that location along the circle.
The following figure demonstrates the working of consistent hashing:

In consistent hashing, the addition of a new server impacts only the immediate neighboring server. This neighboring server is required to share its data with the newly added server while the other servers remain unaffected. As shown in the figure below, adding another server S6S_6S6 impacts only server S5S_5S5. Now, the request R4R_4R4 is served by the S6S_6S6 instead of S5S_5S5.
Adding new servers via consistent hashing is scalable because it involves minimal changes to existing servers. This is attributed to the fact that only a small fraction of the total keys (data) need to be relocated. The hashes are distributed randomly, so we expect that the request load (to store or retrieve data) will be evenly distributed across the circle on average.

Unlike simple hashing, consistent hashing ensures that a minimal number of keys need to move when servers are added or removed from the circle. However, in some cases the request load is not equally distributed in practice. Any server that manages a significant volume of data has the potential to become a bottleneck. That server will experience an excessive influx of data storage and retrieval requests, leading to a decrease in overall system performance. As a result, such situations are commonly known as hotspots.
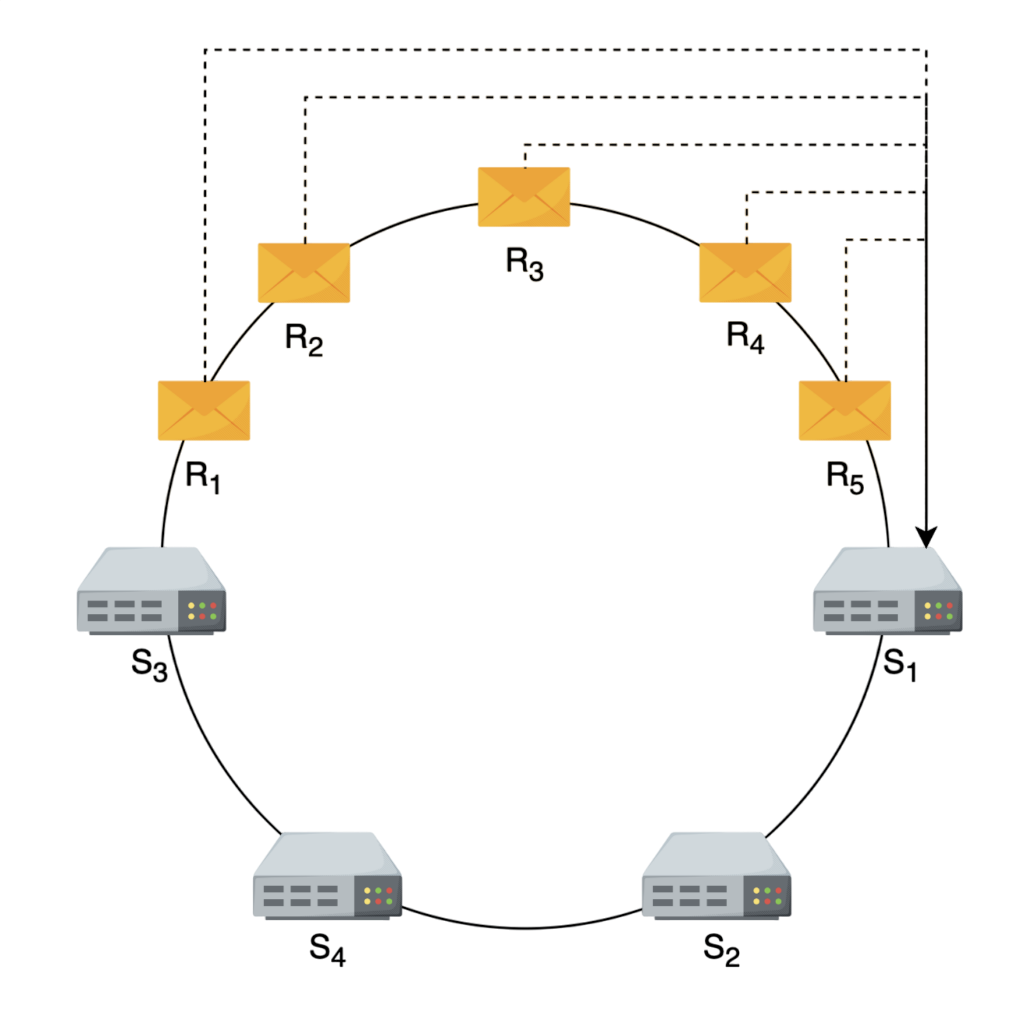
As shown in the figure below, most of the requests are between the S3S_3S3 and S1S_1S1 servers. Now, S1S_1S1 has to handle most of the requests compared to other servers, and it has become a hotspot.
How to avoid hotspots
To prevent hotspots, we employ virtual servers to ensure a more balanced workload distribution across all servers. By virtual servers, we mean that we assign each server to multiple locations on the circle. For this purpose, instead of utilizing a single hash function, multiple hash functions are applied to each server’s ID.
For example, let’s consider the scenario where three hash functions are employed. For every server, we calculate three hashes and position them on the circle. We use only one hash function for the data request (keys). Whenever a request lands on the circle, it is directed to the closest server encountered while moving clockwise. This way, with each server represented at three positions, the request load is distributed more evenly.
Note: Consistent hashing assumes that the average number of keys stored on each server isKSfrac{K}{S}SK. Here,KKKis the total number of keys, andSSSis the number of servers placed on the circle.
Furthermore, if a server has more hardware capacity than others, additional virtual servers representing it can be added using additional hash functions. This way, it will occupy more positions on the circle and handle a large number of requests.
Let’s look at some practical use cases of consistent hashing to show its importance in the system design.
Use cases of consistent hashing
Following are some of the important use cases of consistent hashing in the system design domain.
Web caching and content delivery networks (CDNs)
Consistent hashing has widespread use in the domain of content delivery networks (CDNs) and web caching. Content delivery networks (CDNs) are made to efficiently provide users with online content by distributing the content geographically to several cache servers that are closer to the end users. As the amount of content and the number of users grow, CDNs must scale while maintaining high performance. Also, they must ensure that content is evenly distributed to prevent any server from becoming a bottleneck.

Consistent hashing is used in CDNs to efficiently map content to cache servers. When a user requests a file, a CDN uses a hash function to assign the file to a cache server. Consistent hashing ensures that the assignment changes minimally when servers are added or removed. This is important for cache efficiency because it prevents a massive redistribution of files and invalidating caches that would occur with traditional hash functions. By minimizing cache invalidation, consistent hashing enhances the user experience through faster load times and reduces bandwidth costs by avoiding unnecessary file transfers from persistent storage.
Distributed databases
Consistent hashing is also utilized by distributed databases such as Amazon DynamoDB and Apache Cassandra to partition data. These databases are designed to distribute large data across multiple servers while ensuring scalability and performance. Consistent hashing is used to evenly distribute the data among the available servers so that each server bears a fair amount of the data load.

When a data entry (like a table row) is added to the database, the system uses consistent hashing to determine which server should store the entry. Consistent hashing decreases the impact on system performance by requiring only a small amount of data to be moved to the new servers when new servers are added to the database cluster to manage rising loads. It also creates a clear mapping between data entries and the servers that manage them, which makes managing failovers and data replication easier.
The above two case studies highlight the importance of consistent hashing in the system design domain. Let’s further look at the other dimensions where consistent hashing bears paramount importance in designing a system.
Consistent hashing importance in system design
The primary objective of consistent hashing is to distribute data among multiple servers in a balanced and scalable manner, facilitating the decentralization of resources. Apart from this, consistent hashing holds great importance in system design due to its various properties, discussed below:
- Scalability: Distributed systems can easily scale by adding or removing servers from the network due to consistent hashing. This scalability ensures seamless expansion without requiring extensive data transfer because it is achieved with minimum data remapping when servers are added or removed. This seamless expansion of a system also allows us to handle an ever-increasing number of users while accessing the servers.
- Low latency: Consistent hashing reduces network latency and improves data usage by distributing data evenly across servers. This approach ensures that requests are directed to the closest or most appropriate server, reducing the time required to process data. Additionally, consistent hashing is important in distributed caching systems where cache keys are evenly distributed to maximize cache hits and minimize latency by reducing the need to fetch data from slower storage systems.
- Fault tolerance: In distributed systems, server failures, additions, and removals are common. Consistent hashing lessens the impact of such occurrences and reduces the chance of data loss and service interruptions brought on by server changes or failures.
- Load balancing: Through uniform data and workload distribution across servers, consistent hashing also prevents any single server from becoming a bottleneck. This load-balancing mechanism optimizes system performance in distributed systems, ensuring efficient resource utilization and fair task allocation across the servers.
Scalability, low latency, fault tolerance, and load balancing are important requirements for an efficient system design. All these can be achieved by distributing resources (databases, caches, or any other servers) using consistent hashing. Therefore, consistent hashing holds great importance in achieving a good system design.
To enhance your system design expertise, explore some high-quality resources: